LoRA笔记
LoRA (Low-Rank Adaptation),一种LLM的微调方法
选择LoRA是因为它通过向变换器层注入可训练的低秩矩阵,主要针对语言模型组件,从而高效适应大型预训练模型。这种方法显著减少了可训练参数的数量,使微调在计算上更轻松,同时保持了强有力的性能。(Kvasir-VQA-x1数据集中介绍)
以Qwen2.5-7B为例:
- 7B = 70亿参数 × 2 Bytes ≈ 14G (只是加载或推理)
- 若全参微调需要120G左右:
- 激活值 ≈ 22G
- 优化器状态 ≈ 56G
- 梯度 ≈ 28G
- 模型权重 ≈ 14G
1 Bytes(字节) = 8位2进制数
精度:FP16 = 2 Bytes/参数
理解Rank和微调
秩(Rank)
矩阵中线性无关的行或列的数量,真正包含独立信息的维度。且行秩=列秩
而研究发现,大模型的权重$w$(满秩)在微调时,微调的变化$\Delta w$ 具有低秩性。
所以优化,从微调整个$w$矩阵,转变为只微调变化的低秩的$\Delta w$,就可以达到接近全参微调的效果。
$\Delta w$可以用两个更小的矩阵进行表示
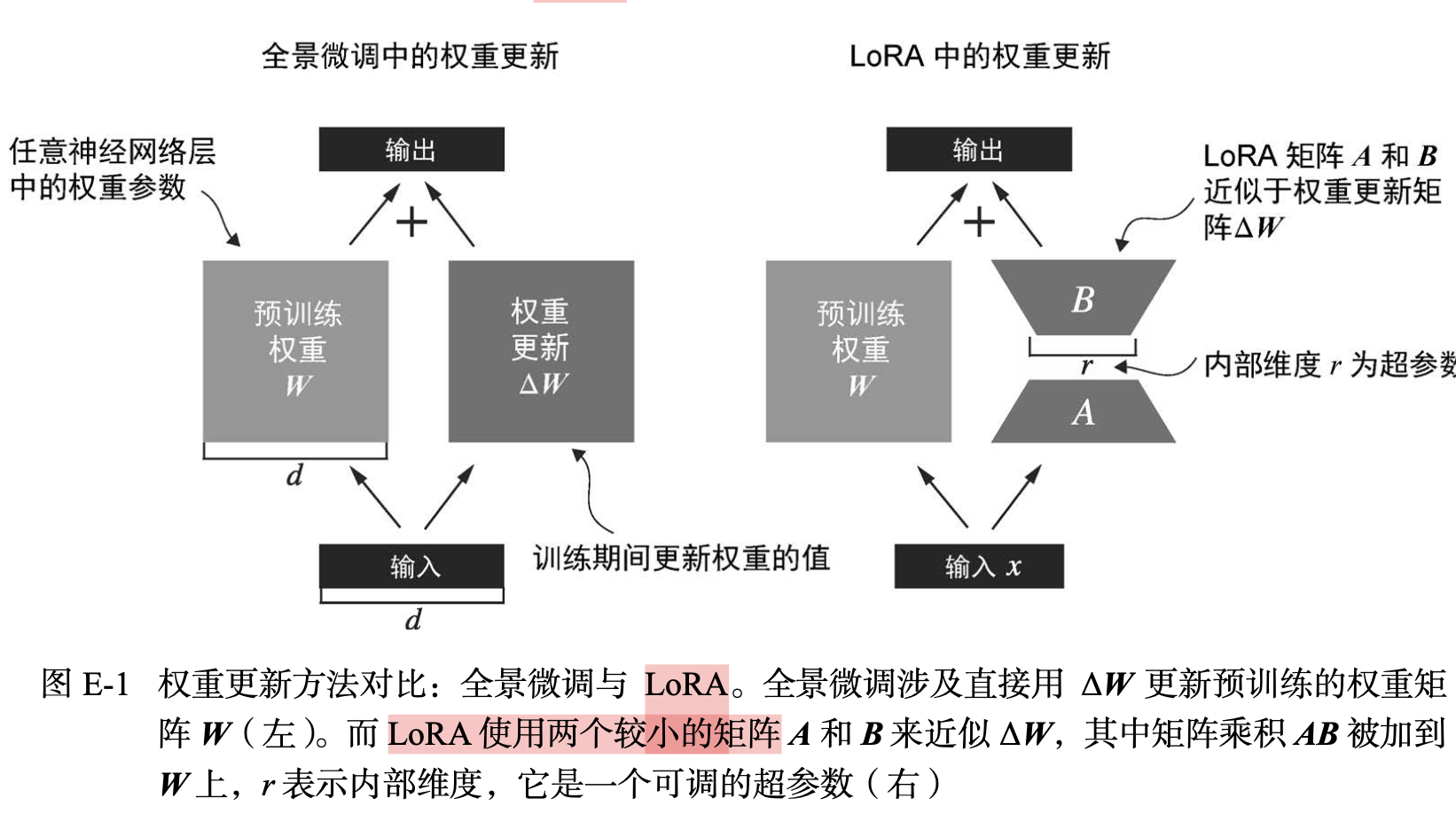
LoRA核心过程
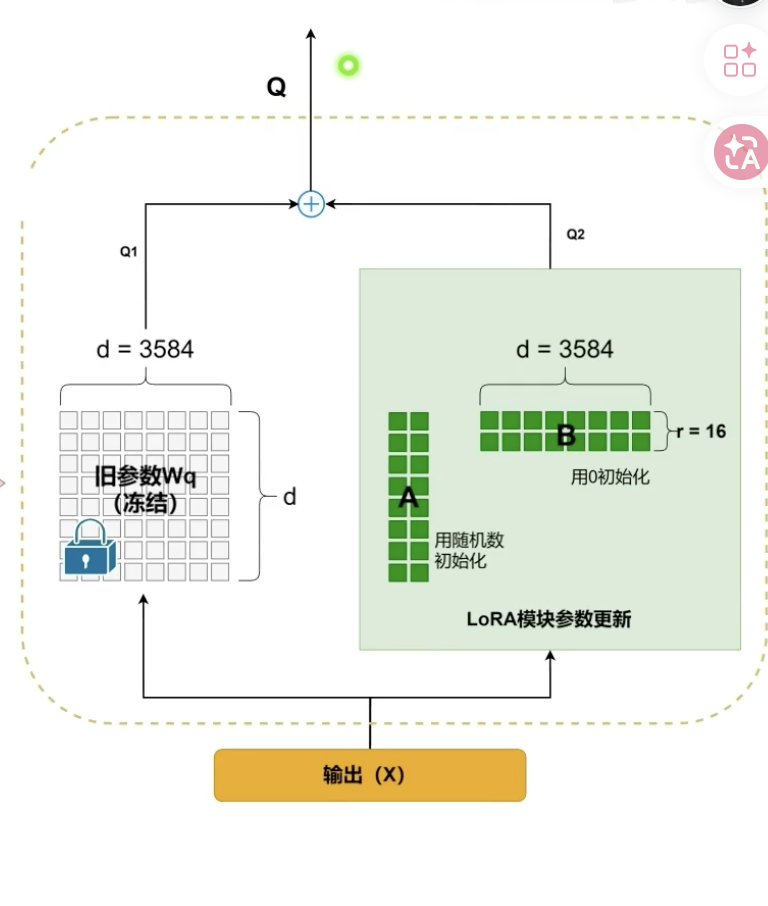
$$ \begin{aligned}
Q &= Q_1 + Q_2 \
&= W_qX+\Delta W_qX \
&=W_qX + ABX \
&= (W_q +AB)X \
&= W_q^{Merged}X\end{aligned} $$
- A : LoRA 模块降维矩阵,使用随机数初始化
- B: LoRA模块升维矩阵,使用全0矩阵初始化
- x输入到模型后,原参数冻结(不参与反向传播),仅在LoRA模块的两个小矩阵进行参数更新
- 最后原参数和更新后的内容相加得到更新后的结果
LoRA在哪里使用
主流大模型(Qwen、LLaMA)采用Transformer-Decoder Only架构,由24层堆叠而成。
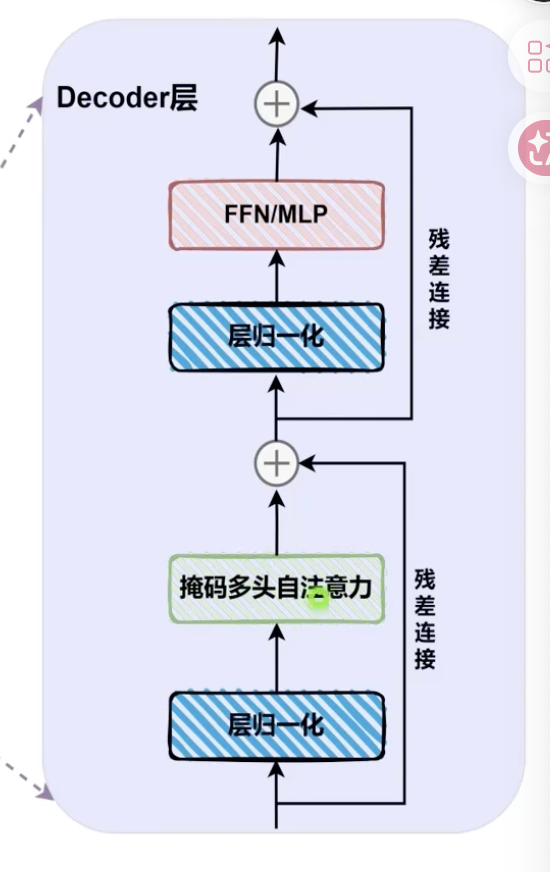
LoRA作用与每个Decoder的掩码多头注意力 。
初步实验:注意力的$W_q$和$W_v$
对Decoder的多头注意力的QKV的Q、V权重的更新使用LoRA方法:
- $W_q$:关注的信息
- $W_v$:决定提取的内容
结果:显著改变了注意力的分布,若显存资源有限,或任务简单,可以只调整这两个矩阵。
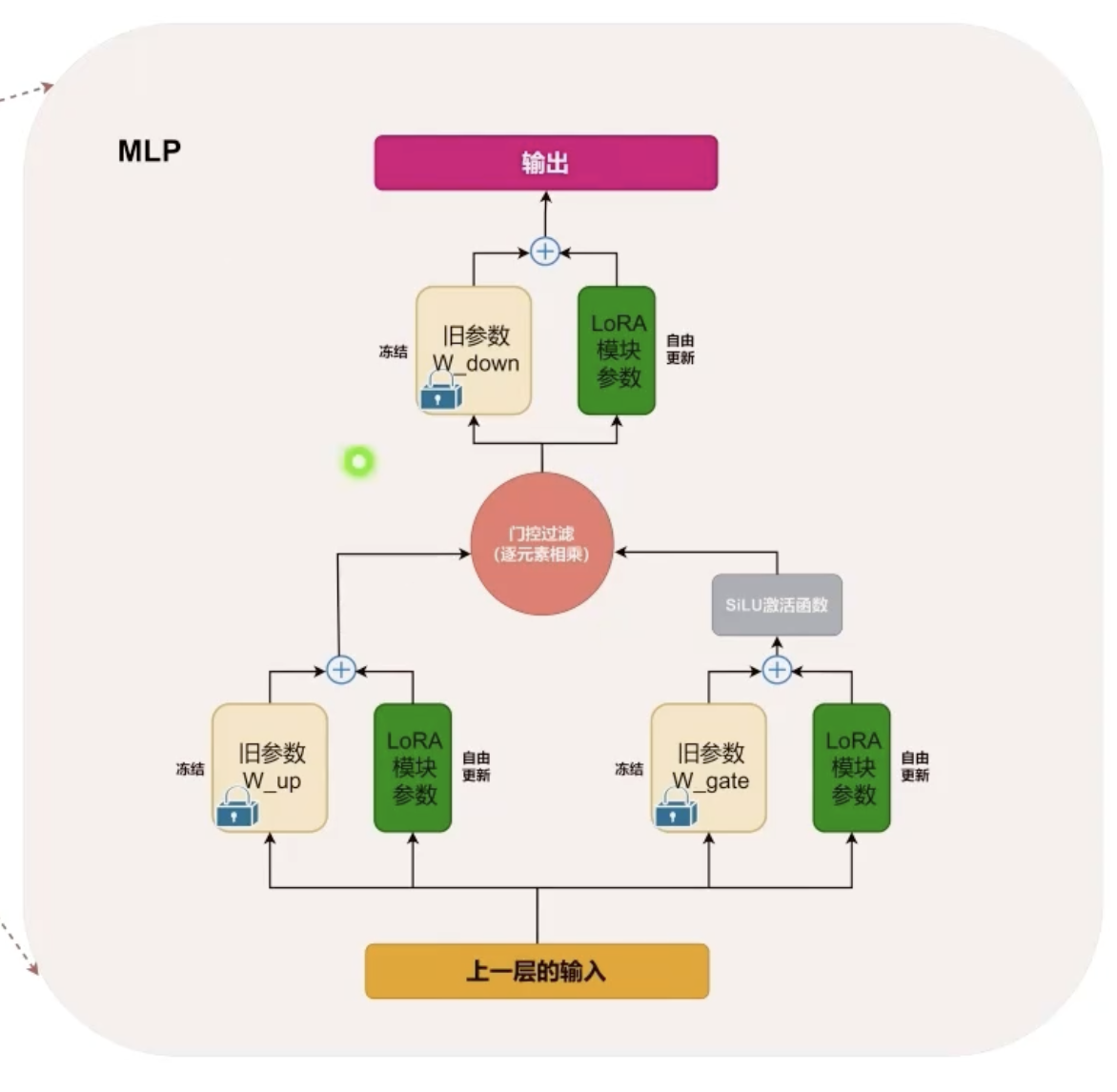
MLP部分插入LoRA
根据进一步研究(如QLoRA)发现,仅对Attention微调难以改变模型深层行为,而MLP才是大模型中只是存储与重组的核心。
LLM中MLP通常是三层线性投影“
- $W_{up}$:映射到高维空间
- $W_{gate}$:控制信息流
- $W_{down}$:映射到原维度
大厂面试
**Q1:为什么A是随机初始化,B是全0?为什么不能都随机或者都为0初始化?
**
-
在初始阶段,LoRA模块需要保持透明,也就是乘积为0,保证不会对原有性能表现造成干扰。
-
为保证反向传播顺利进行,需要损失函数对A、B的梯度不同时为0
情况一:若AB均为全零矩阵
$$ \begin{aligned} \frac{\partial \mathcal{L}}{\partial A} &= \frac{\partial \mathcal{L}}{\partial Q} \cdot Z^T \ &= \frac{\partial \mathcal{L}}{\partial Q} (BX)^T \ &= \frac{\partial \mathcal{L}}{\partial Q} X^T B^T \end{aligned} $$
对A矩阵求偏导,可以看到最后会有一个矩阵为$B^T$, 而B为0,则损失函数对A梯度为0。
$$ \frac{\partial \mathcal{L}}{\partial B} = \frac{\partial \mathcal{L}}{\partial Z} \cdot X^T = \left( A^T \frac{\partial \mathcal{L}}{\partial Q} \right) X^T $$
对B同样的,也会导致损失函数对B的梯度为0,无法顺利更新情况二:A、B都不为0,观察更新函数:
$$ \begin{aligned}
Q &= Q_1 + Q_2 \
&= W_qX+\Delta W_qX \
&=W_qX + ABX \
&= (W_q +AB)X \
&= W_q^{Merged}X\end{aligned} $$则:
$$
W_{final} = W_{pretrained} + LargeNoise
$$
情况三:一个为0,一个随机。(其实A、B反过来也可以)
既不影响原来模型的表现,又能保证梯度能顺利更新。

